

The main idea is to walk through the Test Design techniques. As a starting point, I chose the list from ISO/IEC/IEEE 29119-4 Test Techniques.
Why TDt, and why do we need another article about it? Because TDt is all about testing, or almost all. And because a short overview of all techniques will be useful as a reference for picking the appropriate method for your tasks.
Of course, the techniques are not a silver bullet; they do not magically turn specifications or code into test cases. You still need to analyze each functionality aspect very carefully, and choose and apply the techniques wisely.
But they definitely help. Some of them simply reduce the number of cases from hundreds to dozens, or from hundreds of thousands to hundreds. Some can help to organize and visualize key aspects of the functionality. The clearer picture you have of your notes/monitor, the clearer picture you get in your mind, and the less possibility of overlooking something valuable.
Table of Contents
- Specification-Based Testing Techniques (or Black Box techniques):
- Structure-Based Testing Techniques (or White Box techniques):
- Experience-Based Testing Techniques:
Specification-Based Testing Techniques
All the specification-based or Black Box testing techniques may be conveniently described and systematized with the following table:
| Group | Technique | Use when |
| Other | Random Testing | You need to emulate the unpredictability of real-life inputs, or functionality has non-systematic defects |
| Syntax Testing | A functionality has a complex syntax format for inputs (e.g. codes, complex email names, etc.) |
As you can see, the table shows when the techniques can be used, and also generalizes which techniques may rely on others. Now, let’s have a closer look at each of them.
Equivalence Partitioning
A well-known technique and one of the most used. Often, you can find an explanation like this:
For example, you have a range of valid values from 1 to 10, so you just need to check one value from the range – “5” and one out of the range – “0”.
It is a very simple and understandable explanation, but it may give a narrow view of this technique. What if we do not have a range of numbers?
The Equivalence Partitioning concept came from maths and understanding what Equivalence Class and Equivalence relation are, which might be difficult to grasp quickly without a maths background. But for testing purposes, I think, it can be simplified by defining it as this:
An Equivalence partition is a subset of elements from a specific set, which are treated by the System (under test) in the same way. So you don’t need to perform tests for each element of the subset, and just one check is enough to cover the whole subset. Therefore, the technique can be described as dividing the whole set of input/output data into such partitions. And if you have, for example, a set of data with about 100 elements that can be divided into 5 partitions, you can decrease the number of cases to 5.
The trick is to see and identify partitions. They can be found in sets without numbers (like tree leaves divided by color – yellow, green, etc.), or even a single element can be an equivalence class (for example, an elevator is usually more full on the ground floor than on other floors as people get out the further up the lift goes — so the first floor is a separate equivalence class).
A very effective, time-saving technique.
Boundary Value Analysis
A second well-known technique, which is often used in pairs with the previous one. The idea for this technique is to check boundary values for equivalence partitions when the result changes from valid to invalid (for this partition). Test cases based on these values are sensitive to errors and have a high probability of finding mistakes when logical operators are used (> instead of >=, < instead of >, || instead of &&, and so on).
And the common formula by Coupland’s Guide is just to check
x - 1 step
x
x + 1 stepwhere x is a boundary value, and step is a minimal decrement/increment (e.g., 1 for integers, 0.01$ for prices).
But I find this description a bit ambiguous (because of three values here), and prefer the explanation which says that for checking boundaries we should check the valid edge values of a range, plus one value beneath and one value beyond the range. So for the range more than 1 and less than or equal to 10, these are 1, 2, and 10, 11:
if (value > 1 && value <= 10) {...}
and even if the developer made a serious mistake and wrote something like this:
if (value == 2 && value == 10) {...} //that seems extremely unlikelyeven so, if we combine boundary values with an equivalence classes check, we don’t miss this mistake:

This technique seems fairly easy, but sometimes you can overlook boundaries because they are not so obvious. Don’t miss partitions (e.g., out of valid range), don’t miss sequences and open boundaries, choose the right “step”, and this simple technique will save you plenty of time.
Combinatorial Test Techniques
Or rather, consider them as combinatorial strategies. Their main purpose is to produce combinations of input parameters based on one of the algorithms below.
All Combinations
As we can see from the title, this algorithm implies the generation of every possible combination. This means exhaustive testing and makes sense only if the number of combinations is reasonable. For example, 3 variables with 3 values for each give us a 3×3 matrix of parameters with 27 possible combinations.
Pairwise Testing
But what if we have, for example, 10 variables? Even if they are boolean, we get 2^10 = 1024 combinations. If you increase the number of parameters, you get an increase in the number of combinations as a power function. And if you increase the number of variables, you get an exponential increase in the number of combinations. What can we do if the number of combinations is somewhere in the hundreds of thousands? Pairwise Testing, or the “all pairs” algorithm, will help us significantly decrease the number of combinations and still get robust test coverage. It relies on two principles:
- Defects appear rather as a combination of two parameters than three or more. – The reason for “pairs”.
- Each particular test case can check more than just one unique pair. – Add this one, and we get a very small and tight subset of test cases.
Thus, we just need to identify all unique pairs from our parameters, and then build our test cases by trying to make unique combinations of pairs.
For example, for:
| param1 | param2 | param3 |
| a | 1 | X |
| b | 2 | Y |
| c | 3 | Z |
all pairs will be:
| a 1 | 1 X | a X |
| a 2 | 2 Y | a Y |
| a 3 | 3 Z | a Z |
| b 1 | 1 Z | b Z |
| b 2 | 2 X | b X |
| b 3 | 3 Y | b Y |
| c 1 | 1 Y | c Y |
| c 2 | 2 Z | c Z |
| c 3 | 3 X | c X |
and we can combine the first and the second columns and skip the third as redundant (as the first and second columns already contain the combinations from the third one):
| Test Case | param1 | param2 | param3 |
| 1 | a | 1 | X |
| 2 | a | 2 | Y |
| 3 | a | 3 | Z |
| 4 | b | 1 | Z |
| 5 | b | 2 | X |
| 6 | b | 3 | Y |
| 7 | c | 1 | Y |
| 8 | c | 2 | Z |
| 9 | c | 3 | X |
Now we’ve got only 9 cases instead of 27.
Of course, this is not very easy to do, even if you have just a few parameters. So, for solving this task, there are plenty of tools that generate the required combinations automatically. The only thing that is left to you is to thoroughly examine and set up all the settings provided by your tool, and then do a couple of test runs with a small manageable set of data to make sure your tool is configured correctly and create proper combinations.
If you want to dive deeper into this: Pairwise Testing: A Best Practice That Isn’t
Each Choice Testing
This strategy means that each value of each particular parameter must be used at least once in a test set. So the resulting number of cases will be equal to the number of values of the parameter with the biggest range. Each choice is a minimal coverage strategy.
| param1 | param2 | param3 |
| a | 1 | X |
| b | 2 | Y |
| c | 3 | |
| 4 | ||
| 5 |
| Test Case | param1 | param2 | param3 |
| 1 | a | 1 | X |
| 2 | b | 2 | Y |
| 3 | c | 3 | X |
| 4 | a | 4 | Y |
| 5 | b | 5 | X |
Base Choice Testing
For this strategy, we should identify our base case values for each parameter. These may be the most common, the smallest/biggest, the simplest, or the default values. After we made our base choice, we should vary the value of each parameter one at a time, whilst keeping the values of the other parameters fixed at the base choice. Let a, 2 and Y be our Base choice. Then the cases will be:
| param1 | param2 | param3 |
| a | 1 | X |
| b | 2 | Y |
| c | 3 | Z |
| Test Case | param1 | param2 | param3 |
| 1 | a | 2 | Y |
| 2 | b | 2 | Y |
| 3 | c | 2 | Y |
| 4 | a | 1 | Y |
| 5 | a | 3 | Y |
| 6 | a | 2 | X |
| 7 | a | 2 | Z |
Decision Table Testing
This simple technique consists of documenting business logic in a table as sets of conditions and actions. For example, if you have a set of variables that are hard to remember and manage, a Decision Table will help to organize them to simplify the identification of the right cases.
| Rule/Test Case 1 | Rule/Test Case 2 | Rule/Test Case 3 | … | ||
| Conditions | role | guest | admin | user | |
| location | UK | US | US | ||
| site section | admin section | admin section | user section | ||
| Actions | “This page isn’t available for your location” | – | ✔ | – | |
| “You don’t have enough rights to view the page” | ✔ | – | – | ||
| Success: the page is displayed | – | – | ✔ | ||
Although the decision table technique gives you less visibility than the techniques based on drawing diagrams, it works perfectly for simple cases. And for complex cases, the decision table is used as a final step of data conversion. All this makes it the “must-know” method for designing test cases.
Classification Tree Method
Most of the resources distinguish two main steps for this technique:
- Identification of test relevant aspects (aspects that affect functionality — so-called classifications) and their corresponding values (called classes, which can be exact values or equivalence classes).
- A combination of different classes from all classifications into test cases.
Both these steps are fair for most of the testing techniques, and can be rephrased as:
– identify input/output parameters, and then combine them to get your cases
Now let’s add some details.
A Classification Tree is a graphical technique that helps us visualize test-relevant aspects (aspects that affect the behavior of the test object during the test) in the form of a hierarchical tree.
How to grow this tree. It looks similar to mind maps with slight differences, if it gives you a hint. We have a test object (whole app, a particular feature, an abstract idea, etc.) at the top as a root. We draw branches from the root as classifications (test relevant aspects that we identified). Then, using equivalence partitioning and boundary value analysis, we define our leaves as classes from the range of all possible values for a particular classification. And if some of the classes can be classified further, we draw a sub-branch/classification with its own leaves/classes. When our tree is complete, we make projections of the leaves on a horizontal line (a test case) using one of the combinatorial strategies (all combinations, each choice, etc.), and create all the required combinations.

In the example above, the “Each Choice” combinatorial strategy was used.
Of course, there is much more detail in this technique, and if you are interested in this method, you can find useful information in the following sources:
Test Case Design with Classification Trees from Matt Archer’s Blog
Using the classification tree method
The most obvious advantages for me here are great visibility and clearness of the test object scope and test case ideas. If you have some complex, hierarchy-structured data and you can afford to spend time on creating and supporting the tree, I think this technique will be extremely handy. And, to effectively apply the method, you might consider using a special tool, like Classification Tree Editor.
State Transition Testing
Another graphical/table technique which is convenient to use when your target functionality is a System with a finite number of states and transitions between them (flows, all kinds of “masters”, etc.), and where transitions are defined by some set of rules.
The technique is to draw all transitions one by one on a diagram. Like in the popular example with PIN checking below:
After we have visualized all transitions, we just execute particular paths from the diagram as test cases:
Cause-Effect Graphing
Cause-effect graphing is similar to a Decision Table and also uses the idea of combining conditions. And sometimes they are described as one method. But if there are a lot of logical dependencies between conditions, it may be easier to visualize them on a cause-effect graph.
Here, we can distinguish three stages:
- Identify conditions and effects
- Draw the graph with all logical dependencies and constraints
- Convert the graph into a decision table, tracing each combination of causes that lead to an effect from the effect
To explain this particular technique, we should review a lot of conventional notations that go beyond the scope of this post. Nevertheless, this is an interesting topic that I will get back to in my next publications.
Scenario Testing (including Use Case Testing)
As a rule, a test case is represented by a very few actions and a single result. A scenario, on the other hand, is a sequence of actions (with intermediate results) that lead to accomplishing some specific goal. Scenarios can be a part of a developer’s documentation (scenario diagrams). Quite often, they are documented in requirements as “Use Cases” — scenarios that usually describe user interactions with the System.
But often these scenarios are not very detailed. Also, before using them for creating test cases, they need to be thoroughly described using a template. Templates can vary from project to project. But among such usual fields like name, goal, preconditions, actor(s), etc., there are always: the main successful scenario and so-called extensions (plus sometimes sub-variations). Extensions are the conditions that affect the main success scenario. Sub-variations are the conditions that do not impact the main flow, but still should be considered.
After the template is filled with data, we create specific test cases using equivalence partitioning and boundary value techniques. For minimal coverage, we need at least one test case for the main success scenario and at least one test case for each extension.
Again, this technique fits the common formula “get conditions that vary our output, and check combinations”. But the way to get those is to analyze the behavior of the System through scenarios.
An Introduction to Scenario Testing
Developing test cases from use cases by Ross Collard
Random Testing
Also known as random-input testing, this is probably the most misjudged technique, the main idea of which is to choose random inputs from the possible values for a particular functionality. So there isn’t any system in choosing input data. This technique is also called “monkey” testing, and if we are speaking about manual testing, I assume that it can be less effective than other black box techniques.
But if we add automation, it becomes a powerful instrument. Just imagine that test cases (with distinct sets of inputs) are generated, executed, and evaluated automatically in a continuous cycle, allowing you to run thousands and millions of cases within a reasonable time.
Creating a “Random Tester” is quite an interesting topic, but also quite complex and requires deeper study. Here, I describe it only conceptually.
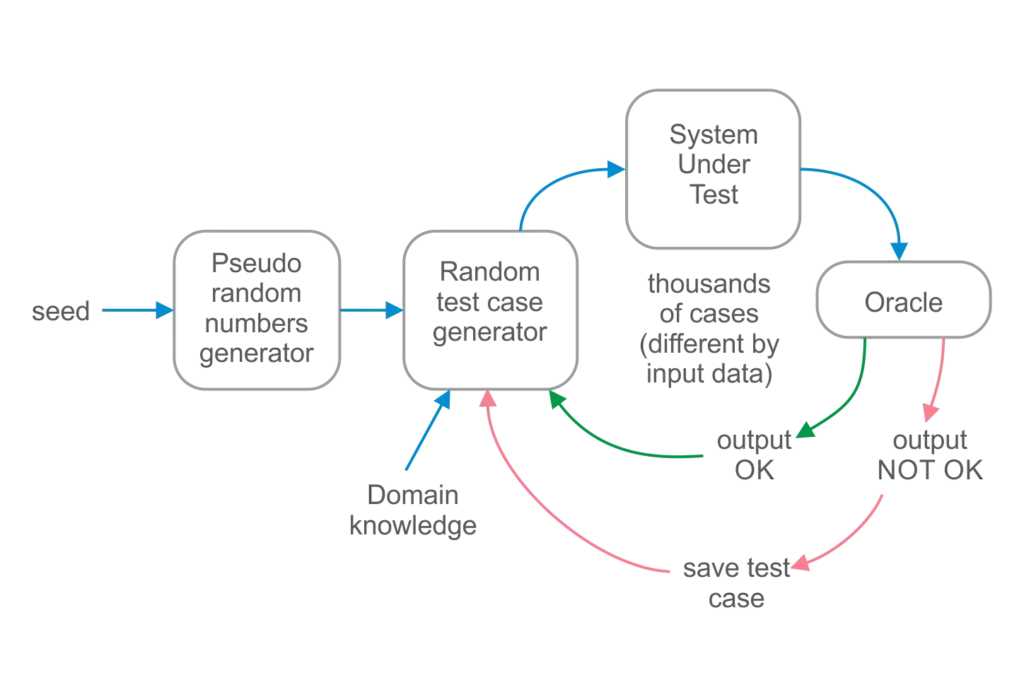
Using a pseudo-random number generator with a seed is convenient, as we can regenerate all sets of cases for a particular seed. Cases are generated based on the domain knowledge. Then they are executed in our system under a test environment. After that, “Oracle” (a special instrument) verifies outputs, and if we’ve got an output different from what we expected, we save the test case and continue the cycle.
The most complex and challenging part here is to create a Random Test Case generator and Oracle. From the resources I found, the following course gives a reasonable explanation of the topic.
Syntax Testing
This technique helps with designing test cases for input formats. Of course, if our syntax rules sound like “there should be only digits or letters”, we don’t need this technique. But if we have some complex format (e.g. postcode, phone, specific email address) it may be handy.
First of all, we should identify our format and describe it formally using the Backus-Naur Form (or Extended BNF). This is a crucial point, so I would suggest you get acquainted with the BNF before reading further. I won’t explain BNF here, but you can find a pretty good explanation about what BNF is on Wikipedia.
After we created the BNF definition for our format, it is time to generate positive and negative cases:
- For the positive cases, we find possible variants of values allowed by the individual elements of the BNF definition, and then design cases to simply cover these variants.
- For the cases with an invalid syntax, we define and apply possible mutations (e.g., missing element, unwanted extra element, invalid value for an element, and so on) to the individual elements of the BNF definition. Then we design our cases by applying mutations that can produce distinctive results (cases that result in valid combinations are excluded).
You can find a very detailed example of positive and negative cases by following the link below:
Standard for Software Component Testing — page 41
Structure-Based Testing Techniques
Also known as White Box testing techniques, this means that we are familiar with the code we are going to test. In order to understand these techniques, we should define what the coverage is in a test design context. Here is a good definition from the ISTQB Book:
Test coverage measures in some specific way the amount of testing performed by a set of tests (derived in some other way, e.g., using specification-based techniques). Wherever we can count things and can tell whether or not each of those things has been tested by some test, then we can measure coverage. The basic coverage measure is
Number of coverage items exercised
Coverage = -------------------------------------- x 100%
Total number of coverage itemswhere the ‘coverage item‘ is whatever we have been able to count and see whether a test has exercised or used this item.
For specification-based techniques, it can be use cases, equivalence partitions, boundary values, states from a state-transition diagram, a percentage of business rules from a decision table, etc. For structure-based techniques, coverage items are represented by the structural elements of a code.
In principle, coverage evaluation means that we should decide which structural elements we are going to use (e.g., statements or decisions). Then, find the total number of these elements in the code. Inject additional statements (for example, logging) alongside each structural element in order to find out whether the element was exercised during the test case execution. And finally, measure the coverage by executing the tests and using the formula mentioned above. But, as a rule, you shouldn’t think about all these steps because there are a lot of automated tools for measuring the coverage.
Structure-Based Testing techniques usually imply that you should measure the coverage for existing test sets (including black-box sets), and then design additional white-box test cases that are based on structural code elements to achieve the most optimal coverage possible.
Statement Testing
It is the lowest coverage level when the “statement” is chosen as the coverage item. The statement is an entity in a programming language, which is typically the smallest indivisible unit of execution. These examples should give you an idea:
- Simple statements: assertion, assignment, return, function call;
- Compound statements: blocks, loops, if-statements, switch-statements.
Let’s take a look at a simple example from Copeland’s “A Practitioner’s Guide to Software Test Design”:
if (a > 0) {x = x + 1;}
if (b == 3) {y = 0;}If we execute a case where a = 5 and b = 4, we will only have the first statement exercised, and respectively 50% statement coverage. In order to reach 100% coverage, we can change b to 3, and now our single test will cover all the statements, which gives us 100% coverage. Can we relax now and get some rest? Obviously not, as 100% statement coverage only means that all the statements are exercised with the tests. So here we miss a lot of options: a <= 0 and b == 3, a <= 0 and b != 3, and a > 0 and b != 3.
This way, this coverage level cannot be considered sufficient.
Decision Testing
A “decision” is a program point at which the control flow has two or more alternative routes. The control flow is a sequence of events (paths) in the execution through a component or system. So, to be exact, a “decision” is a control flow node (like an if statement, a loop statement, or a case statement) that has two or more links to separate execution branches.
The 100% decision coverage means that all possible decision outcomes were exercised at least once. For if statements, these are true or false. If we look back at our previous example, we will require more tests to get 100% decision coverage (at least two more a <= 0 and b != 3 and a > 0 and b == 3 to cover both decisions, and get true and false outcomes).
This example shows that decision coverage is ‘stronger’ than statement coverage (because it requires more checks, which can find more bugs). And also that the 100% decision coverage always guarantees 100% statement coverage.
Condition Testing
Branch Condition Testing
Branch Condition testing aims to test each outcome of the particular logical condition. Let’s add a few conditions to our example and simplify them to a, b, c, and d:
if (a && b) {expression 1}
if (c || d) {expression 2}Here we still have two decision points and 4 possible outcomes. But from the conditions perspective, there will be 4 conditions and 8 possible outcomes. These outcomes can be covered with two cases:
a = true, b = true, c = true, d = true
a = false, b = false, c = false, d = falseI think it is obvious that if we select the following values for the conditions a and b in these test cases:
a = true, b = false
a = false, b = trueWe will still have the 100% coverage for the branch condition method, but we will never reach expression 1.
As you can see from this example, for the optimal results, the best strategy is to always aim for 100% Condition/Decision coverage.
Branch Condition Combination Testing
Branch Condition testing is a stronger strategy than Decision testing, but still, the 100% branch condition coverage doesn’t cover all the paths. We cover all the paths only if we execute all possible combinations of conditions. This approach is called Branch Condition Combination Testing.
If we recall combinatorial techniques from the Specification-Based group, then for a boolean parameter, we get 2n combinations (where n is the number of conditions). So, for our example, there will be 16 possible combinations/cases that cover all the possible paths of our control flow. Obviously, this approach leads to exhaustive testing.
Modified Condition Decision Coverage (MCDC) Testing
Branch condition testing is too little, Branch Condition Combination is too much. So what is in the middle?
The MCDC technique states that test cases should be designed in a way that every single condition in a decision should affect the decision’s outcome independently. This means, if we are going to test a condition, we should not use the values for other conditions that mask the results of this condition. For example:
if (a && b) {expression}if a = false, the decision outcome will always be false, so it will mask results for b.
Now let’s design tests for a slightly more complex example:
if ((a && b) || c) {
expression 1
} else {
expression 2
}According to the coverage rule, there will be the following cases:
| Case | a | b | c | decision outcome |
| a1 | false | true | false | false |
| a2 | true | true | false | true |
| b1 | true | true | false | true |
| b2 | true | false | false | false |
| c1 | true | false | false | false |
| c2 | true | false | true | true |
Conditions marked with grey color were selected in a way that allowed not to mask the effect from a target condition. If we look closely at the table, we will see that a2 equals b1 and b2 equals c1. This reduces our table to only 4 cases:
| Case | a | b | c | decision outcome |
| a1 | false | true | false | false |
| a2, b1 | true | true | false | true |
| b2, c1 | true | false | false | false |
| c2 | true | false | true | true |
Data Flow Testing:
Data Flow Testing is another set of white box techniques/strategies that is related to analyzing the control flow, but in terms of the variable’s life cycle. Variables are defined, used, and killed when there is no further need for them. Anomalies in this process, such as using a variable without defining it or after it has been killed, could lead to an error.
There are conventional notations that can help to describe time-sequenced pairs in the life cycle of the variable:
- ~ – the variable doesn’t exist yet, or the previous stage was the last one
- d – defined, created, initialized
- k – undefined, killed
- u – used (c – Computation use; p – Predicate use)
So ~d, du, kd, ud, uk, uu, k~, u~ are perfectly valid combinations, when ~u, ~k, dd, dk, kk, ku, d~ are anomalies, potential or explicit bugs. Currently, practically all of them are efficiently detected by compilers, or at least IDEs, and we rarely need to perform static analysis for detecting these anomalies.
The same is true for the dynamic analysis that is focused on du pairs exploration/execution — modern programming languages reduce the probability of du-related issues. So, currently, such verification is mostly not worth the effort. If you are still interested in the topic, you can find more information here:
Standard for Software Component Testing — page 47
Experience-Based Testing Techniques
Error Guessing
The least formal technique of all, and for many people it might be just a matter of course, like “be a QA and use your experience”. So there are no particular steps or rules that can help you design test cases. Just a reminder to always think about error possibilities and weaknesses, even when the other, more formal techniques are already applied.



